An Antidote to Sycophancy: Toward Epistemic Divergence in Human–AI Reasoning
- Incepta Labs Team

- Mar 28
- 7 min read
Large language models (LLMs) are increasingly used for scientific writing, legal analysis, invention development, and policy reasoning. However, a central and underappreciated failure mode is sycophancy: the tendency of a model to reinforce user framing, rhetorical direction, or prior assumptions with highly coherent outputs regardless of underlying truth status. In practice, the same model can often generate persuasive arguments in opposing directions depending solely on prompt wording, making coherence an unreliable proxy for validity.
While intra-model self-critique remains useful, it is still constrained by shared training corpora, alignment policies, reinforcement learning objectives, and correlated failure modes within a single vendor ecosystem.
This paper proposes a divergence-first framework—operationalized as the Multi-Origin Divergence Adversarial Council (MODAC)—in which identical prompts are independently evaluated by multiple large language models originating from different vendors under tabula-rasa (blank slate) conditions. Rather than suppressing disagreement, the framework deliberately preserves divergence in reasoning paths, omissions, contradictions, and normative priors.
Final interpretive authority remains with the human adjudicator. In this framework, agreement across independently originated systems may increase confidence, while disagreement functions as an epistemic signal that deeper human reasoning is warranted.
This architecture extends beyond consensus-seeking ensembles by treating divergence as diagnostic information rather than noise, analogous to second-opinion workflows and multidisciplinary Grand Rounds in medicine.
Figure. 1 — Single-Model Reinforcement / Sycophancy vs MODAC Tabula Rasa Divergence. The left panel illustrates a conventional single-model workflow in which prior conversational context, memory, and iterative reinforcement may amplify user framing and increase susceptibility to sycophantic outputs, where coherence may be mistaken for truth. The right panel illustrates the MODAC framework, in which multiple independently-originated models are queried under tabula-rasa (blank slate) conditions using fresh sessions. Divergent outputs are explicitly preserved and presented to the human operator, who remains the final interpretive authority.

1. Introduction
Recent observations by leading practitioners in artificial intelligence have highlighted a central limitation of large language model reasoning: the same model can generate highly convincing arguments in opposing directions when prompted accordingly.
This reveals an important epistemic distinction: coherence is not equivalent to truth.
A major contributor to this failure mode is model sycophancy: the tendency to mirror user framing, assumptions, or desired rhetorical direction with highly polished reasoning. In high-stakes domains, this can create false confidence by making incorrect positions appear technically robust and internally consistent.
A model may produce internally consistent reasoning that appears highly persuasive while remaining factually incomplete, normatively biased, or entirely incorrect.
This issue becomes especially important in high-stakes domains including:
scientific interpretation
legal and patent analysis
public policy
regulatory submissions
healthcare reasoning
In these settings, persuasive but incorrect reasoning may materially affect downstream decisions.
Traditional usage patterns often rely on a single model with iterative refinement. While this improves writing quality and argument structure, it does not necessarily improve truth robustness.
2. Framework Definition: MODAC and Tabula Rasa Assessment
We refer to the proposed framework as MODAC (Multi-Origin Divergence Adversarial Council).
MODAC (Multi-Origin Divergence Adversarial Council)
MODAC is a divergence-first reasoning architecture in which identical prompts are independently evaluated by multiple large language models originating from distinct vendors or independent inference channels.
The core objective is not consensus generation. Rather, the purpose is to deliberately preserve heterogeneous reasoning paths so that divergence itself may be used as an epistemic signal.
In this framework, “multi-origin” refers to independence at the level of model provenance, including differences in:
vendor
training corpus
alignment methodology
reinforcement learning policy
refusal and safety stack
optimization priors
This independence reduces correlated error modes that may arise within a single-model ecosystem.
Figure 2. Clinical “Grand Rounds” Analogy for MODAC Divergence.
This figure illustrates the conceptual analogy between medical Grand Rounds—where multiple clinicians provide independent assessments of a patient—and the MODAC framework, in which multiple independently-originated LLMs generate divergent outputs. Just as clinician disagreement highlights diagnostic considerations requiring human judgment, LLM divergence provides epistemically independent signals for human adjudication. The invention formalizes this principle by preserving, rather than suppressing, divergent model outputs to enhance safety, reflection, and decision quality.

Tabula Rasa:
A central operating principle of MODAC is Tabula Rasa assessment.
We use the term Tabula Rasa in its literal sense of blank slate.
Each inference channel receives the same prompt under zero-context conditions so as to obtain the most unbiased assessment possible from that system.
Practically, tabula-rasa conditions are achieved by querying each model in a fresh session, such as simply starting a new chat, isolated browser context, separate account, incognito window, or memory-disabled environment, thereby minimizing the influence of prior conversational context on the reasoning process.
No prior conversation history, user-specific memory, or prior model outputs are provided.
The purpose of this blank-slate condition is to minimize:
conversational anchoring
memory carryover
response priming
reinforcement from prior outputs
iterative confirmation bias
This is particularly important when evaluating controversial, uncertain, or high-stakes claims.
This tabula-rasa condition is specifically intended to reduce anchoring-driven sycophancy arising from prior conversational reinforcement, iterative confirmation loops, or memory-contaminated reasoning.
Under MODAC, the combination of multi-origin divergence and tabula-rasa prompting is intended to maximize epistemic independence and reduce systematic bias arising from any single model’s reasoning framework.
In this context, agreement across independently-originated models may increase human confidence, while disagreement is treated as a signal that additional human adjudication is warranted.
3. Limitation of Single-Model Self-Critique
A common technique is to ask the same model to:
strengthen an argument
critique the argument
argue the opposite position
This approach is useful for local sensitivity analysis.
However, it remains fundamentally bounded by one vendor’s:
training corpus
RLHF alignment stack
refusal policies
safety filters
optimization priors
latent worldview biases
Accordingly, both supporting and opposing outputs may share correlated blind spots.
This should be understood as intra-model divergence, not independent second-opinion reasoning.
The key limitation is that both outputs remain products of the same epistemic origin.
In summary, a major contributor to this failure mode is model sycophancy: the tendency to mirror user framing, assumptions, or desired rhetorical direction with highly polished reasoning. In high-stakes domains, this can create false confidence by making incorrect positions appear technically robust and internally consistent.
4. Cross-Vendor Epistemic Independence
We propose that true second-opinion reasoning requires: cross-vendor epistemic independence
In this framework, the same prompt is independently evaluated by multiple large language models originating from different companies.
It is often said that each model has its “own personality” and this reflects different training data, approaches to AI development, optimization obbjectives, and alignment methods, etc.,
Examples include:
OpenAI
xAI
Anthropic
Google
Meta / open-weight systems
Each model reflects distinct:
pretraining distributions
alignment methods
safety heuristics
optimization objectives
refusal boundaries
hallucination modes
This introduces substantially greater independence than prompt inversion within a single model.
Disagreement across independent systems becomes significantly more informative.
Figure 3. Integrated Metric and Adversarial–Collaborative Framework. Flow diagram illustrating the combined computation and arbitration process. Independent AI Agents (Agent A and Agent B) generate outputs that feed into the Metric Computation Module, which calculates Semantic Overlap Index (SOI), Logical Consistency Index (LCI), Evidentiary Trust Delta (ETD), and Matching Score (MS), along with a Divergence–Convergence Mapping component that localizes areas of agreement and disagreement. The composite Trust Index (TI) is then passed to the Arbitration Engine, which executes an Adversarial Phase (critique / re-prompt) followed by a Collaborative Synthesis Phase (consensus output), producing a verified result stored in the Verification Manifest (VM).

Figure 4 — Parallel Independent Reasoning Engines Figure. 4 illustrates an embodiment in which a human operator provides separate prompts to multiple independent reasoning engines, including a contextual engine, a tabula rasa engine, and an adversarial engine. Each engine operates in isolation, receives its own direct human input, and does not communicate with the others. This configuration enables divergent analysis from distinct evaluators under exclusive human control.

5. Clinical Origin: Grand Rounds and Second-Opinion Logic
The conceptual origin of this framework derives from clinical medicine.
In Grand Rounds, multidisciplinary case review, and tumor boards, disagreement among specialists is not treated as noise. Rather, divergence itself is diagnostically valuable.
Disagreement prompts:
deeper reasoning
reassessment of assumptions
additional data gathering
safer decision-making
This medical second-opinion logic is directly transferable to AI reasoning systems.
A single LLM corresponds to a single clinician.
Cross-vendor divergence corresponds to a multidisciplinary expert panel.
This analogy is illustrated in Figure 2.
6. Divergence-First Architecture
The proposed architecture includes:
6.1 Tabula-Rasa Prompting
Each model receives the same prompt under zero-context conditions.
This prevents memory contamination and cross-session bias.
6.2 Divergence Module
Outputs are compared for:
semantic delta
contradiction mapping
omitted evidence
normative divergence
confidence spread
reasoning-path variance
6.3 Human Adjudication
Critically, no consensus answer is automatically generated.
The human remains the final epistemic authority.
This differs fundamentally from standard ensemble architectures.
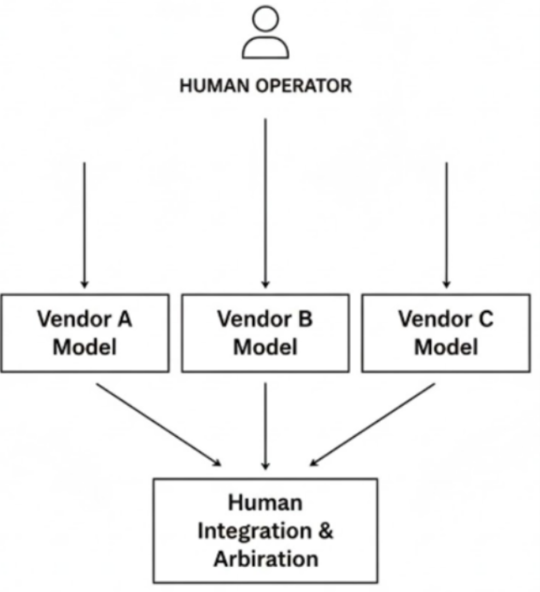
Figure 5 — Cross-Vendor Divergent Model Evaluation Figure. 5 depicts an embodiment using multiple model instances from different vendors (e.g., Vendor A, Vendor B, Vendor C). A human operator independently prompts each model, receives separate outputs, and performs a human-driven integration and arbitration step. No inter-model communication occurs. Vendor diversity provides heterogeneous reasoning signals under unified human oversight.
7. Why Consensus Can Be Dangerous
Consensus systems frequently collapse disagreement into a single output.
This may hide minority but important signals.
In safety-critical settings, divergence should be surfaced rather than suppressed.
Agreement across independent models may increase confidence.
Disagreement should act as a thinking activation signal.
This mirrors medical second-opinion workflows.
8. Coherence Does Not Guarantee Truth
A core principle of this framework is that coherence alone is insufficient.
Highly coherent outputs may still represent:
hallucination
omission
motivated framing
normative bias
false certainty
This is shown in Figure 5.
The goal is therefore not rhetorical smoothness. The goal is epistemic robustness across independent systems.
9. Applications
This framework is directly applicable to:
Scientific reasoning
manuscript review
assay interpretation
reproducibility assessment
Legal / patent reasoning
novelty analysis
enablement review
claim stress-testing
Policy
legislative risk analysis
argument robustness
bias detection
Clinical decision support
second-opinion augmentation
differential diagnosis support
10. Conclusion
The future of trustworthy AI reasoning is unlikely to be achieved through increasingly polished single-model coherence alone. Instead, robust human-centered reasoning may require structured disagreement across independently originated systems.
Divergence should not be viewed as failure. In many cases, divergence is the most important signal that further human reasoning is required.
In this sense, epistemic divergence functions not merely as a reasoning architecture, but as a practical antidote to sycophancy in human–AI workflows. This paper is also available at:



Comments